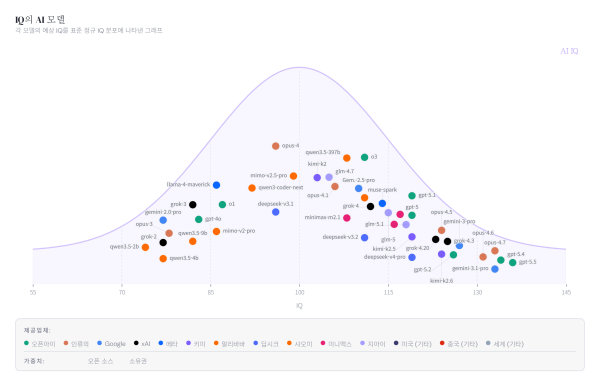
最新の生成AIモデルを単一スコアで比較する「AI IQ」が公開された。エンジニア兼起業家のライアン・シェイ氏は5月14日(現地時間)、複数の公開ベンチマークを人間のIQ尺度に換算し、各モデルの性能を一覧できる同プロジェクトを発表した。
AI IQは、複数のベンチマーク結果をそのまま並べるのではなく、各モデルがIQの分布上でどの水準に位置するかを可視化するのが特徴だ。モデル性能の時系列推移に加え、IQと感情知能(EQ)の比較、実利用を想定したコスト効率も確認できるようにした。
比較対象には、GPT-5.5、AnthropicのClaude Opus 4.7、Google Gemini 3.1、Grok 4.3、Kimi K2.6、Qwen 3.6、DeepSeek V4、Muse Sparkなどが含まれる。公開時点で最高スコアだったのはGPT-5.5で、GPT-5.4、Gemini 3.1 Pro、Opus 4.7が続いた。
もっとも、このスコアは人間向けのIQテスト結果そのものではない。AI IQは、抽象推論、数学推論、プログラミング推論、学術推論の4分野にまたがる公開ベンチマークを「推定IQ」に換算し、その平均値から総合スコアを算出する仕組みだ。対象ベンチマークはARC-AGI-1、ARC-AGI-2など12種類としている。
スコア算出では補正も加える。暗記や学習データの混入によって高得点が出やすいベンチマークは、特定項目だけで総合点が過度に押し上げられないよう調整するほか、欠測データがある場合は保守的に補完する設計とした。
表示機能では、企業別の絞り込みにも対応する。例えばxAIでフィルターを設定すればGrokシリーズのみを表示でき、世代ごとの性能変化を追える。時系列グラフのほか、OpenAI、Anthropic、Googleの3社に絞った比較画面も用意した。
コスト面の比較も盛り込んだ。IQと実効コストの関係を示すグラフでは、入力200万トークン、出力100万トークンの処理を想定した価格に、モデルごとのトークン使用効率を反映して算出する。単純なトークン単価ではなく、同じ作業を終えるのに実際にどの程度の費用がかかるかに近い数値だとしている。同じIQ帯でも、GeminiはGPTやOpusより低コストと算出された。
一方で、AIの能力を単一スコアに集約する手法には批判もある。X(旧Twitter)では「AIの能力は分野ごとの差が大きく、単一スコアにまとめると誤解を招きかねない」との指摘が上がった。
AI IQについては、ベンチマーク表を分かりやすく見せる試みとして評価する声がある一方、「推定IQ」をAIそのものの知能と受け取るべきではなく、複数の性能指標を比較するための変換値として捉えるべきだとの見方も示されている。
シェイ氏は「ベンチマーク表や各モデルの宣伝文句だけでは、AIモデルを理解するのが難しくなった」とした上で、「どのモデルが実際に使う価値があるのか、判断しやすくしたい」と述べた。
生成AIを巡る競争では、単純な性能スコアや価格表だけでなく、実利用における使い勝手や効率をどう比較するかが焦点になりつつある。モデル性能の変化が速い中、スコア推移とコストを同時に示すこうした手法が、利用者や企業のモデル選定にどのような影響を与えるのか注目される。