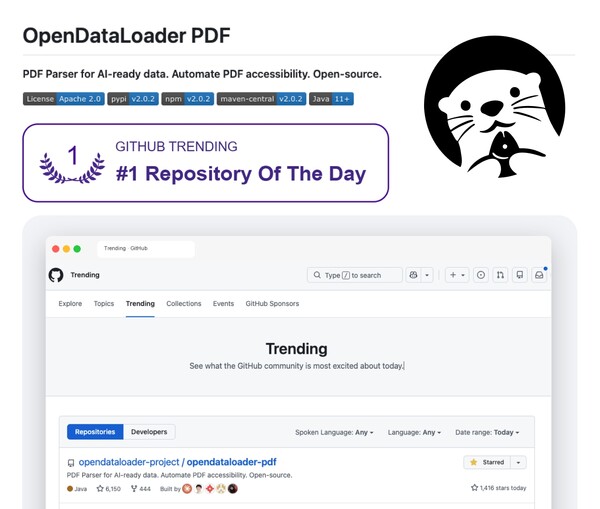
Hancomは3月23日、PDFデータ抽出のオープンソースソフトウェア(OSS)「OpenDataLoader PDF v2.0」が、GitHubの全言語トレンドで20日時点の首位となり、トレンドバッジを獲得したと発表した。
GitHubトレンドは、世界の開発者の関心を集めるOSSをリアルタイムで可視化する指標だ。Hancomによると、OpenDataLoader PDF v2.0は3月21日の1日でスター数を1800以上積み上げ、累計スター数は7000超、フォーク数は500超となった。
OpenDataLoader PDFは、複雑な構造を持つPDF文書をテキスト、表、画像などに分解し、AIが扱いやすい形式に変換する技術。PDFはAI学習で広く使われる文書形式である一方、内部構造が複雑なためデータ抽出が難しく、開発工程のボトルネックになりやすいという。
Hancomは2025年7月、PDF技術の専門企業Duallabと業務提携に向けたMOUを締結し、共同開発に着手した。同年9月に初期版を公開し、2026年3月12日にv2.0をリリースした。
v2.0では、AI方式と直接抽出を組み合わせたハイブリッドエンジンを採用。データを外部サーバに送らず、ローカル環境で動作する。OCR、表抽出、数式抽出、チャート分析のAIアドオン4種を標準搭載し、Doclingなど他社のOSSベースAIモデルとの互換性も備える。
Hancom代表のキム・ヨンス氏は、「今回の成果は、当社の文書データ抽出技術の完成度と実用性が、グローバル開発者コミュニティで直接評価された結果だ。多様な活用を通じ、技術エコシステムを広げられる可能性も確認できた」とコメントした。その上で、「Apache 2.0ライセンスへの移行を通じて、世界の企業や開発者が自由に活用・拡張できるオープンなPDFデータプラットフォームへと発展させていく」と述べた。