中国のAIスタートアップZ.aiは、文書理解に特化したマルチモーダルOCRモデル「GLM-OCR」をオープンソースで公開した。9億パラメータの軽量モデルながら、複雑な文書レイアウトを高精度に解析できる点を特徴とする。
IT系メディアのGigazineが2月4日(現地時間)に報じた。Z.aiによると、GLM-OCRは複雑なレイアウトを含む文書の解析と情報抽出を高精度に行うことを目指して開発したという。
モデルは、画像情報と言語情報を統合的に処理できるよう設計した。写真やスキャン画像から文字とレイアウトを読み取る視覚処理モジュールと、抽出した内容を文章として整理する言語処理モジュールを組み合わせている。
学習方式も見直し、1回の推論で扱える情報量を増やすことで、認識精度と学習効率を高めたとしている。
処理はまず文書のレイアウトを解析し、その結果を基に文字を認識する2段階構成を採用した。表や注釈などが混在する文書では構造が崩れやすいという従来OCRの課題に対応し、文書全体の配置を踏まえた認識を可能にするという。
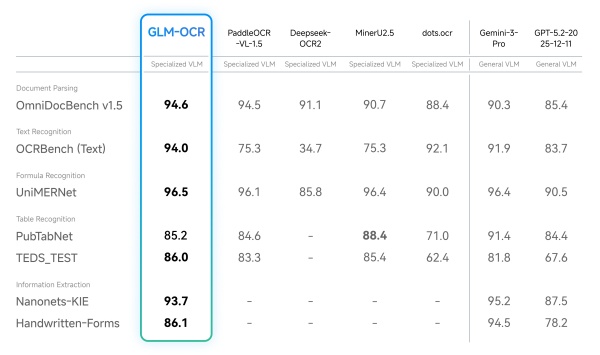
性能面では、文書認識ベンチマーク「OmniDocBench V1.5」で94.62点を記録した。数式や表といった認識難度の高い要素や、文書内容を項目ごとに整理して抽出するタスクでも高い精度を示したとしている。
運用面では、軽量モデルである点も特徴に挙げる。PCなどのローカル環境でも比較的高速に動作し、文書を外部サーバに送信せず社内環境で処理できるという。
処理速度はPDFで毎秒1.86ページ、画像で毎秒0.67枚。複雑な表や複数言語が混在する文書にも対応し、結果はHTMLとJSON形式で出力できるようにした。
GLM-OCRは、Hugging Face上の「zai-org」リポジトリで公開している。モデル本体はMITライセンスで提供し、文書レイアウト解析に用いた一部コンポーネント「PP-DocLayoutV3」にはApache License 2.0を適用する。
GLM-OCRは、文書認識に大規模モデルが必要とされてきた見方に一石を投じる事例といえそうだ。企業にとっては、外部クラウドに文書を送らず、社内PCやサーバでOCRを実行できる点が導入メリットになりそうだ。
オープンソース化を受け、実務での活用事例が広がるかどうか、また軽量OCRを巡る競争がさらに活発化するかが注目される。