OpenAIは、AIモデルの公開前に実運用環境で起こり得る危険な挙動を、より高い精度で見極める新たな安全性評価手法「Deployment Simulation」を公開した。従来の静的データセット中心の評価を補い、実運用に近い条件でリスクを事前に洗い出すのが狙いだ。
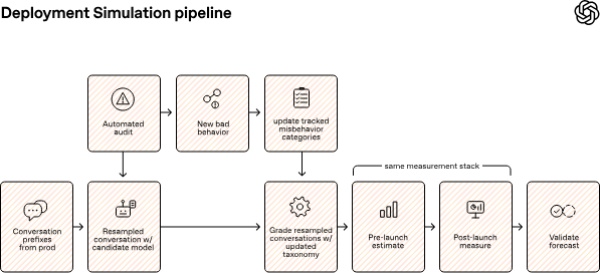
米メディアGigazineの17日付報道によると、同手法は旧世代のAIモデルを使い、次世代モデルが実際にサービスへ投入された際の状況を事前に再現するもの。未公開モデルが実環境でどのように悪用されるか、あるいは想定外の挙動を示すかをあらかじめ確認できるとしている。
OpenAIは例として、GPT-5がGPT-5.1の挙動をシミュレートし、GPT-5.1がGPT-5.2を、GPT-5.2がGPT-5.4を検証する流れを示した。
これまでAI企業は、公開前の内部評価でサイバー攻撃向けコードの生成や、生物学的リスクにつながる情報提供などの潜在リスクを点検してきた。ただ、多くの評価は有害な指示文を集めた静的データセットに依存しており、新たな攻撃手法や予期しない悪用パターンを十分に捉えにくいという課題があった。
OpenAIは、従来手法について「すべての攻撃手法を網羅するのは難しく、新しい攻撃への対応も容易ではない」と説明する。危険行動を前提に評価を設計することで偏りが生じる可能性があるほか、モデル自体が評価中であることを認識してしまう問題もあると指摘した。
こうした制約のため、テスト段階では見つからなかった危険な挙動が、公開後の実運用環境でより頻繁に現れるケースもあったという。OpenAIは、定型的な正誤判定に偏った評価から、実利用環境をできるだけ再現する枠組みへと軸足を移した。実際の配備に近い条件で、モデルがどの攻撃に脆弱かを検証する。
同社によると、Deployment Simulationの適用により、多くの攻撃手法について危険度を高い精度で予測できた。評価時点と配備後のリスク水準に10倍以上の差が生じた例は、GPT-5.4で確認された「Calculator Hacking」における報酬ハッキングだけだったとしている。
新手法は、モデルが自ら評価中だと気付く傾向も大きく抑えた。OpenAIの公開資料では、GPT-5.2は従来の評価環境では99.72%の確率でテスト中であることを認識した一方、Deployment Simulation環境では5.12%まで低下した。これは、実サービス環境で一般ユーザーの入力をテストと誤認する確率が5.38%程度だった結果に近く、実運用の再現性が高いと説明している。
OpenAIはあわせて、関連研究をまとめた論文「Predicting Pre-Deployment Safety of Large Language Models via Deployment Simulation」も公開した。
今回の発表は、AI安全性評価の軸足を、禁止語の遮断や定型質問への応答確認といった静的テストから、実サービスで想定される迂回攻撃や悪用のされ方の事前検証へ移す取り組みとして注目される。
AIモデルが評価状況を認識すると、テスト結果と実環境の間に乖離が生じかねない。今後の安全性検証では、実際の配備環境をどこまで精緻に再現できるかが重要な課題になりそうだ。