Upstageは1月6日、自社開発の大規模言語モデル(LLM)「Solar Open 100B」をオープンソースとして公開したと発表した。モデルはHugging Faceで公開し、開発プロセスや技術的な詳細をまとめたテックレポートも公表した。
Solar Open 100Bは、Upstageが中核企業として参加する科学技術情報通信部の「独自AIファウンデーションモデルプロジェクト」における初の成果となる。データ構築から学習までを自社で一貫して手掛け、ゼロから開発したとしている。
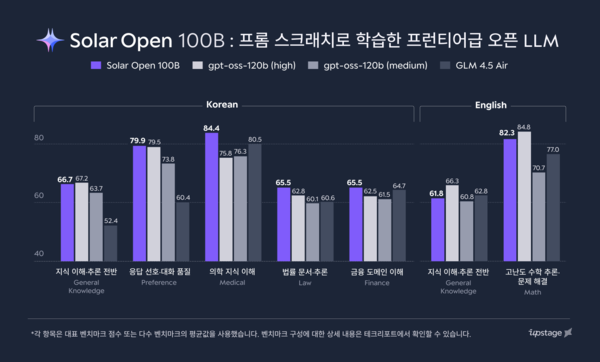
同社によると、Solar Open 100Bのパラメーター数は1020億。比較対象とした中国のAIモデル「DeepSeek R1(DeepSeek R1-0528-671B)」に比べ、モデル規模は15%にとどまる一方、韓国語、英語、日本語の主要ベンチマークではそれぞれ上回る結果を示した。
特に、韓国文化理解を測る「Hae-Rae v1.1」や韓国語知識ベンチマーク「CLIcK」では、DeepSeek R1に対して2倍超の性能差があったという。OpenAIの同規模モデル「GPT-OSS-120B-Medium」と比べても、上回る性能を記録したと強調した。
また、数学、複合指示の実行、エージェント関連タスクといった高度な領域でも、DeepSeek R1と同等の性能を示したとしている。GPT-OSS-120B-Mediumとの比較でも、総合知識やコード生成能力などで競争力を確認したという。
性能向上の要因としては、約20兆トークン規模の高品質な事前学習データセットを挙げた。韓国語データの不足に対応するため、各種合成データに加え、金融、法律、医療などの分野別データを学習に活用したほか、データの学習やフィルタリングの手法も高度化したとしている。
今後は、このデータセットの一部を韓国知能情報社会振興院(NIA)の「AI Hub」を通じて公開し、国内のAI研究エコシステムの活性化につなげる方針だ。
モデル構造では、129の専門家モデルを組み合わせる「MoE(Mixture-of-Experts)」を採用した。実際の演算では120億パラメーターのみを活性化し、効率を高めたとしている。さらに、GPU最適化によって秒間トークン処理量(TPS)を約80%引き上げ、自社の強化学習(RL)フレームワーク「SnapPO」により学習期間を50%短縮したという。
Upstageは今後、独自ファウンデーションモデル開発事業のコンソーシアムに参加するNota、Ravvelup、Flitto、韓国科学技術院(KAIST)、西江大学などと連携し、産業別の特化サービス開発を加速する考えだ。
金融決済院、Law&Company、Makinarocks、VUNO、Okestro、Day1Companyなどとも協力し、金融、法律、国防・製造、医療、公共、教育の各分野でAX(AI転換)を進める。あわせて、AllganizeとUpstageそれぞれの米国・日本拠点を通じ、グローバル市場の開拓も拡大する方針としている。
Upstageのキム・ソンフン代表は「Solar Openは、Upstageが一から独自に学習させたモデルで、韓国の情緒と言語的文脈を深く理解する、最も韓国的でありながら世界に通用するAIだ」とコメントした。そのうえで「今回の公開は、韓国型フロンティアAI時代の幕開けとなる重要な転換点になる」と述べた。