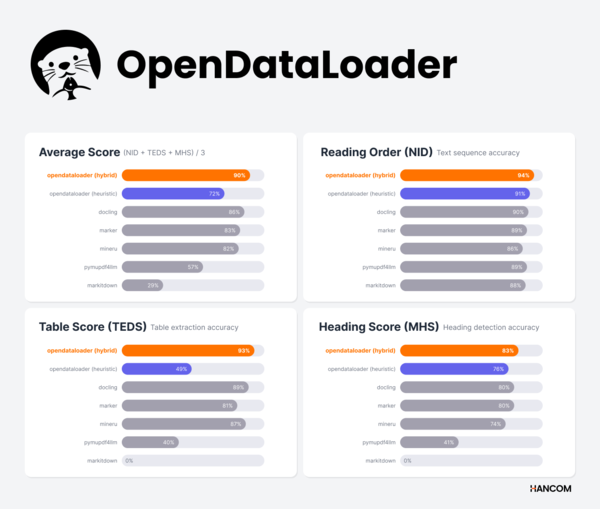
Hancomは3月12日、オープンソースのPDFデータ抽出ツール「OpenDataLoader PDF v2.0」を公開した。同社によると、同分野のベンチマークで首位相当の性能を示したという。
最大の特徴は、AI方式と直接抽出方式を組み合わせたハイブリッドエンジンだ。企業や開発者は、外部サーバにデータを送信しない閉域のローカル環境でも、PDFデータ抽出機能を無償で利用できる。
「OpenDataLoader PDF v2.0」は、文書内の複雑な要素を抽出する4種類の無償AIアドオンを標準で備える。「OCR」は画像ベースのPDFやスキャン文書の文字認識精度を高め、「表抽出」は超軽量AIモデルを用いて結合セルを含む複雑な表構造を解析する。
「数式抽出」は科学・数学論文の数式をローカル環境で認識し、「チャート分析」はグラフやチャートの内容を文章で説明する。
これらのアドオンは、Doclingなど他社のオープンソースAIモデルとも連携しやすいよう実装した。Hancomは、特定団体との公式な提携や後援関係を意味するものではないとしたうえで、既存の技術環境で活用できる互換性を確保した点を強調している。
同社はまた、オープンソースの中核価値である透明性を示すため、ベンチマークテストのデータと再現可能な詳細コードを公式GitHubリポジトリで公開した。
今回のリリースに合わせ、オープンソースライセンスも従来のMPL 2.0からApache 2.0へ変更した。商用利用しやすいライセンスに切り替えることで、外部開発者やグローバルIT企業による導入のハードルを下げる狙いがある。
Hancomは、AIエージェント時代を見据えたエコシステム拡大も進める。2025年にLangChainとの連携を完了しており、2026年にはLangflow、LlamaIndex、Gemini CLIなど各種AIフレームワークとの連携を広げる計画だ。
AIエージェントを支援するMCP(Model Context Protocol)への対応も進めている。
2026年下半期には、独自の文書AI技術を集約した商用AIアドオンを投入する計画。AIが文書構造を分析し、アクセシビリティタグを自動生成する技術も搭載する。
Hancomのチョン・ジファンCTOは、「OpenDataLoader PDF v2.0は、AIハイブリッドエンジンとApache 2.0ライセンスへの移行によって、誰も自由に活用・拡張できるオープンなPDFデータプラットフォームへ進化した」とコメントした。
そのうえで、「今後は商用AIアドオンとアクセシビリティソリューションを通じて、世界中のPDF文書がAIに活用されるだけでなく、すべての人に開かれた文書になるよう、グローバルなエコシステムを主導していく」と述べた。