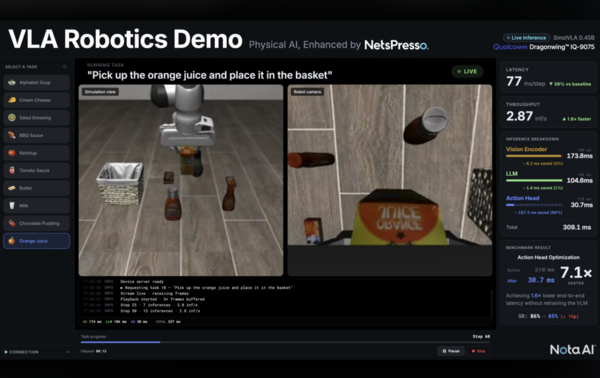
Notaは5月29日、ビジョン・言語・行動(VLA)モデルをQualcommの最新エッジAIデバイス上で最適化することに成功したと発表した。ロボットの動作生成時間を約85.8%短縮し、推論速度は最大7倍に高めたという。
VLAモデルは、カメラなどのセンサーで現実環境を認識し、人の指示を理解したうえでロボットの動作を生成するモデルだ。計算負荷が大きく、一般にはGPUサーバー上で動作することが多い。組み込み機器単体でリアルタイム動作させた例は限られている。
今回Notaは、QualcommのエッジAIデバイス「Dragonwing IQ-9075」上で、VLAモデル「SmolVLA 0.45B」を動作させたうえで最適化を施した。
認識・理解の処理は維持しつつ、ロボットの動作生成を担う最終段の最適化に注力した。反復演算を抑えるリアルタイム推論最適化と、ニューラルネットワーク処理装置(NPU)ベースのグラフ最適化を適用した結果、動作生成段階(Action Head)の処理時間は218ミリ秒から31ミリ秒に短縮した。全体の推論時間も505ミリ秒から310ミリ秒に縮小した。作業成功率は86%から85%で、ほぼ同水準を維持したとしている。
この成果は、米カリフォルニア州サンタクララで開かれた「Embedded Vision Summit 2026」で披露した。会場では、来場者が品物を選ぶと、最適化したVLAモデルが対象を認識し、ロボットアームでつかんでバスケットに入れるリアルタイムの体験型デモを実施した。
Notaのチェ・ミョンス代表は「人工知能が現実環境を見て理解し、行動につなげるプロセスは、エッジAIデバイス上で高速かつ安定して処理できなければならない」とコメント。「今回のVLA最適化は、Notaの技術がフィジカルAI時代の中核基盤へ展開可能であることを示す事例だ」と述べた。