Kakaoは1月20日、自社開発の言語モデル「Kanana-2」を刷新し、4モデルをオープンソースとして追加公開したと発表した。公開先はHugging Face。Mixture of Experts(MoE)アーキテクチャの採用により高効率化を進め、NVIDIA A100クラスの汎用GPUでも運用しやすくしたほか、エージェントAIに求められるツール呼び出し性能も高めた。
Kanana-2は、Kakaoが昨年12月にHugging Faceで公開した言語モデル。今回の追加公開では、性能を引き上げると同時に、コスト効率と実用性を重視した改良を加えた。
新たに公開した4モデルの特徴は、高効率・低コスト化に加え、実務での活用を想定したエージェントAI向け機能を強化した点にある。最新の高価なAIインフラに依存せず、NVIDIA A100クラスのGPU環境でも運用できるよう最適化したことで、中小企業や研究者でも高性能AIを活用しやすくしたとしている。
効率化の中核となるのがMoEアーキテクチャだ。総パラメータ数は32B(320億)規模としながら、推論時には状況に応じて3B(30億)のパラメータのみを有効化し、計算効率を高めた。Kakaoによれば、MoEの学習に必要な複数のカーネルも自社開発し、性能低下を抑えつつ学習速度を高め、メモリ使用量も大きく削減したという。
モデルの改良はアーキテクチャや学習データだけにとどまらない。学習プロセスも見直し、事前学習と事後学習の間に「ミッドトレーニング」の段階を新設した。さらに、新しい情報を学習する際に既存の知識が失われる忘却を抑えるため、「リプレイ」手法を導入。これにより、新たな推論能力を追加しながら、既存の韓国語処理性能と一般常識に関する能力を安定的に維持できたとしている。
Kakaoは今回、基本モデル、指示追従モデル、推論特化モデル、ミッドトレーニングモデルの4モデルをHugging Faceで追加公開した。あわせて、研究用途で活用しやすいミッドトレーニング探索向けの基本モデルも提供し、オープンソース・エコシステムへの貢献拡大につなげる考えだ。
Kakaoは、新版Kanana-2の差別化ポイントとして、単なる対話型AIにとどまらず、実務を担うエージェントAIの実装を意識して設計した点も挙げる。高品質なマルチターンのツール呼び出しデータを重点的に学習させることで、指示追従性能とツール呼び出し性能を大幅に高めた。複雑なユーザー指示を正確に理解し、適切なツールを自律的に選択・実行できるようにしたという。
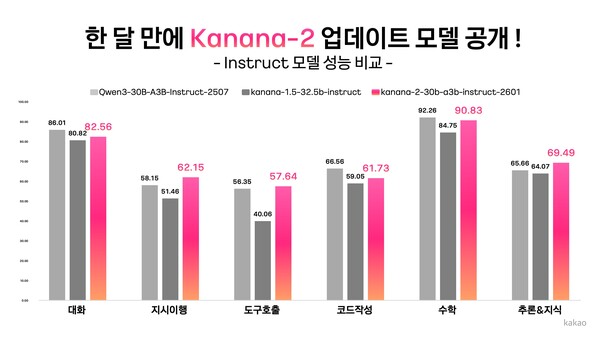
性能評価では、同クラスの競合モデル「Qwen-30B-A3B-Instruct-2507」と比べ、指示追従の正確性、マルチターンのツール呼び出し性能、韓国語性能などで優位性を示したとしている。
KakaoでKananaの成果リーダーを務めるキム・ビョンハク氏は、「新しいKanana-2は、高価なインフラに頼らず、実用的なエージェントAIをどう実装するかを突き詰めた結果だ」とコメントした。その上で、「一般的なインフラ環境でも高い効率を発揮するモデルをオープンソースで公開することで、国内のAI研究開発エコシステムの発展と、企業のAI導入における新たな選択肢につながることを期待している」と述べた。