中国AI初创公司Z.ai开源发布多模态光学字符识别(OCR)模型GLM-OCR,主打复杂文档理解场景。
据Gigazine当地时间2月4日报道,GLM-OCR虽是一款仅有9亿参数的轻量级模型,但目标直指复杂文档的高精度识别与信息抽取。
Z.ai介绍称,GLM-OCR基于“图像+文本”联合理解架构设计,一方面通过视觉模块读取照片、扫描件中的文字及版面信息,另一方面借助语言模块对识别结果进行整理和生成。公司表示,通过改进训练方式,模型在单次推理中可输出更多信息,从而提升识别准确率和训练效率。
在文档处理流程上,GLM-OCR采用“先版面分析、后文字识别”的两阶段架构:先识别文档版面,再基于版面结果同步完成文字识别。Z.ai表示,这一设计有助于弥补传统OCR在表格、注释等元素混杂场景下容易破坏文档结构的不足,使识别结果更贴近原始版面。
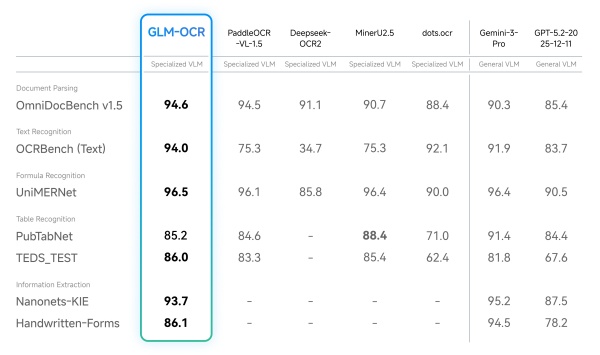
性能方面,Z.ai披露的数据显示,GLM-OCR在文档识别评测OmniDocBench V1.5中获得94.62分。在公式、表格等高难度场景,以及信息抽取任务中,模型也表现不俗。
部署方面,Z.ai强调GLM-OCR的轻量化特性。公司称,即便是在PC等本地环境中,模型也可较快运行,文档无需上传至外部服务器即可在本地完成处理。根据其公布的测试数据,GLM-OCR处理PDF的速度为1.86页/秒,图像处理速度为0.67张/秒。模型还支持复杂表格和多语言混排文档识别,并可将结果输出为HTML和JSON格式。
目前,GLM-OCR已通过AI社区Hugging Face上的“zai-org”仓库发布。模型主体以MIT许可证开源,用于文档版面分析的部分组件PP-DocLayoutV3则采用Apache License 2.0。
报道指出,GLM-OCR也被视为对“文档识别必须依赖大模型”这一普遍看法的挑战。对于企业用户而言,OCR能够在内部PC或本地服务器上运行、无需将文档上传至外部云端,是其主要吸引力之一。随着模型开源,后续能否在实际业务场景中快速积累落地案例,以及轻量级OCR赛道竞争是否进一步升温,仍有待观察。
Z.ai还在社交平台发文称:“Introducing GLM-OCR: SOTA performance, optimized for complex document understanding. With only 0.9B parameters, GLM-OCR delivers state-of-the-art results across major document understanding benchmarks, including formula recognition, table recognition, and information extraction… pic.twitter.com/2c6iSsaXYs”