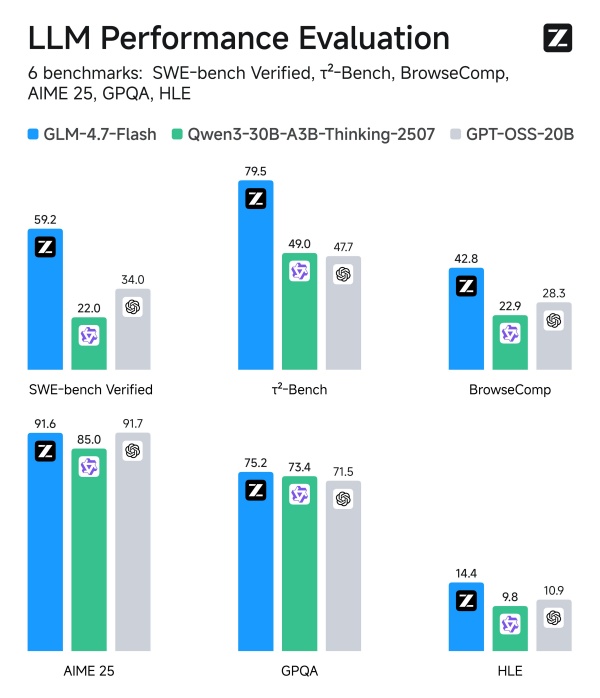
中国AI公司Z.ai发布轻量级模型GLM-4.7-Flash,并表示其性能已超过OpenAI的GPT-OSS-20B。
据日本科技媒体Gigazine 1月20日报道,基准测试结果显示,GLM-4.7-Flash在推理等核心指标上明显领先GPT-OSS-20B。
GLM-4.7-Flash采用MoE(Mixture of Experts,专家混合)架构,总参数量为300亿,激活参数为30亿。在较低激活参数规模下,该模型仍保持了较强的性能表现。
在与Qwen3-30B-A3B-Thinking-2507和GPT-OSS-20B的对比测试中,GLM-4.7-Flash整体表现更优。这两款模型中,Qwen3-30B-A3B-Thinking-2507总参数为300亿、激活参数为30亿,GPT-OSS-20B总参数为210亿、激活参数为36亿。与此同时,在衡量网页搜索能力的BrowseComp测试中,GLM-4.7-Flash也以明显优势领先其他模型。
GLM-4.7-Flash已以MIT许可证开源发布,并在Hugging Face开放下载。BF16版本需要45GB以上VRAM,适配RTX 4090的量化版本预计将于近期推出。
业内普遍关注的是,GLM-4.7-Flash此次采用MIT许可证开源发布。市场认为,具备自由商用属性的高性能轻量级模型出现,可能对当前由OpenAI等大型厂商主导的市场格局带来影响。
与此同时,市场对其可用性的关注也在升温。目前公开的BF16版本仍需要企业级GPU支持,但随着Z.ai预告的量化版本落地,这一情况可能出现变化。若RTX 4090等消费级显卡也能运行,将有助于降低个人开发者和中小企业的使用门槛,并进一步推动开源生态扩张。
这一案例也反映出,AI技术竞争正从单纯比拼参数规模,转向更重视效率。在体量更小、性能更强的轻量级模型持续出现的背景下,高性能AI在家庭场景的普及节奏或将快于预期。