针对外界有关Solar Open 100B“复制中国厂商LLM并在此基础上微调”的质疑,开发商Upstage公开作出回应,称相关说法与事实不符。
1月2日,Upstage CEO SungHoon Kim在首尔江南办公室面向约70名业界及政府相关人士召开说明会,并公开展示了模型训练日志、检查点等核心研发资料。活动同时通过YouTube直播,约2000人在线观看。
SungHoon Kim表示,Solar Open 100B是一款从零训练的模型,权重由公司自行完成训练。他说,从零训练并不意味着不能参考公开的模型架构思路或推理代码写法,但如果直接复用其他已训练模型的权重,就不能再被定义为从零训练。
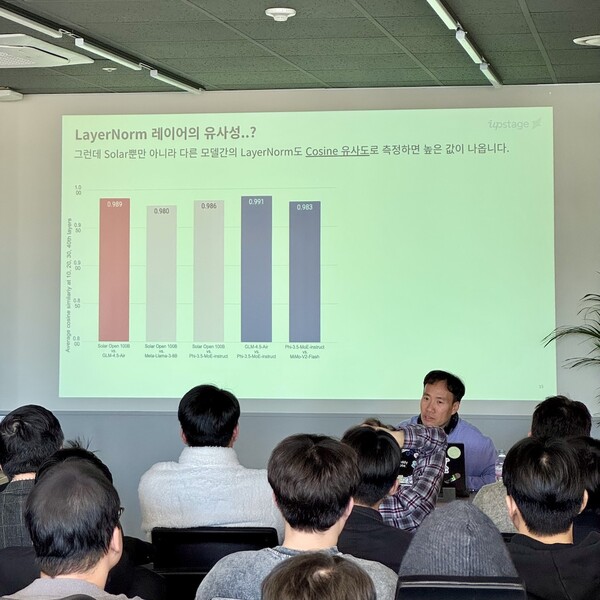
对于外界基于LayerNorm相似性推断模型复用其他权重的说法,SungHoon Kim予以否认,称这更像是统计层面的误读。
他表示,被指存在问题的区间仅占整个模型约0.0004%,比例极低,不能据此推断模型整体复用了其他模型权重。与此同时,他还指出,作为判断依据的余弦相似度并不适合单独用于这一结论。因为余弦相似度主要衡量向量方向的一致性,而语言模型中的LayerNorm通常具有相近的结构和特征,独立训练的模型之间出现较高相似度并不罕见。
针对“Solar Open直接沿用了其他模型Tokenizer”的质疑,SungHoon Kim同样予以否认。他表示,被指控对象的词表规模约为15万个,而Solar Open为19.6万个,双方实际重合的词汇约8万个,占比约41%。他称,若直接沿用同一套Tokenizer,词表重合率通常会超过70%,因此上述数据可以作为Solar Open独立构建分词器的量化依据。
对于“模型结构和代码与特定模型相似”的说法,SungHoon Kim也表示,这一指控与技术现实不符。他称,包括Upstage在内,主流开源LLM开发者通常不会公开训练代码,外界能够参考的多为模型卡或架构说明。在无法获得训练代码的情况下,所谓直接复用并开发模型的说法,在业内看来并不成立。
针对“挪用特定模型源码并篡改许可证”的质疑,SungHoon Kim表示相关说法同样失实。Upstage称,为便于更多开发者使用Solar Open,公司公开了推理代码,并使用了Hugging Face提供的部分开源代码,以提升服务兼容性;相关做法符合Apache 2.0许可证的常规使用方式。公司已更新相关说明,以更准确标注许可证来源。
此次争议源于1月1日。AI初创公司PionicAI CEO SeokHyun Ko在开发者平台GitHub发文称,Solar Open 100B系基于中国Zhipu AI的“GLM-4.5-Air”衍生而来,由此引发市场关注。
由于参与政府自主基础模型开发项目的5支团队首轮评估结果预计将在1月内公布,且首轮评估将淘汰1家企业,上述质疑进一步放大了舆论关注度,Upstage也因此迅速在公司层面展开回应。
与此同时,AI社区内也有不少声音认为,SeokHyun Ko的判断说服力不足。Kakao机器学习研究员Kevin Ko发文称,Solar Open 100B并非由GLM-4.5-Air衍生。
SungHoon Kim表示,公司欢迎基于事实和观点展开健康讨论,但若以断言方式传播失实信息,将对Upstage以及政府推动“AI三强”目标的相关努力造成严重损害。他强调,Upstage将继续通过透明的技术披露证明自身研发能力,并推动本土AI生态进一步扩大。