搜索关键词 本土语境

Games & Commerce
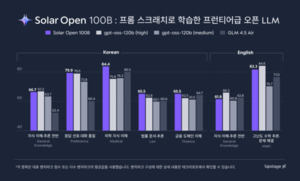
Naver借AI搜索拉动份额回升,韩国新闻入口加速转向YouTube
随着AI Tab测试版推出,Naver在韩国搜索市场的份额出现回升,平均升至66.34%,单日一度达到81.34%。但在新闻消费领域,用户入口正由门户首页和搜索逐步转向YouTube推荐与短视频,搜索与新闻分发的主导权加快分化。
AI & Enterprise
TechRadar:大模型竞争重心转向多语言能力与本土语境理解
TechRadar指出,大模型下一阶段的竞争力将更多取决于多语言能力和对本土语境的理解,而非单纯比拼模型规模或算力。随着AI在全球加速落地,以英语为中心构建的基础模型正日益显现瓶颈,不少模型仍停留在将英语知识转译为其他语言的层面。面向金融、医疗、公共服务等场景,业界认为,模型需要直接基于不同语言体系开展推理,并完善数据、架构和评测体系,以支撑主权AI建设。
AI & Enterprise
韩国科学技术信息通信部公开征集2026年推理数据建设项目
韩国科学技术信息通信部与韩国智能信息社会振兴院(NIA)自4月1日起公开征集2026年推理数据建设项目,总预算为66亿韩元,共设10个课题。项目将围绕LLM以及制造、机器人等Physical AI领域,建设涵盖CoT和因果关系的高质量推理数据,相关成果后续将通过“AI Hub”向企业和科研机构开放。