韩国AI技术企业Upstage于6日宣布,正式开源其自研大语言模型“Solar Open 100B”(以下简称“Solar Open”)。
据介绍,Solar Open是Upstage参与韩国科学技术信息通信部(MSIT)“自主AI基础模型项目”后推出的首项成果。公司表示,该模型采用“从零训练”路线,从数据构建到模型训练均由团队独立完成。目前,Solar Open已在全球开源平台Hugging Face上线,相关技术报告也已同步公开。
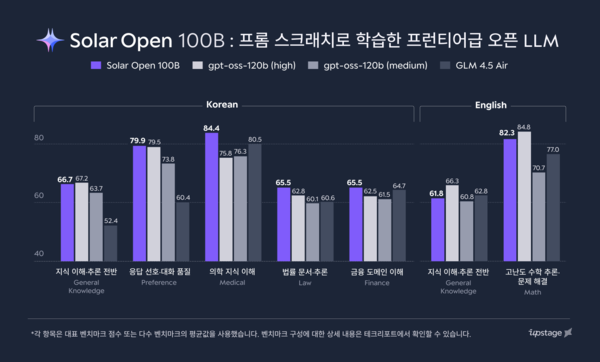
Upstage称,Solar Open总参数量为1020亿。与中国AI模型DeepSeek R1(DeepSeek R1-0528-671B)相比,其参数规模仅为后者的15%,但在韩语、英语和日语三种语言的主要基准测试中,成绩分别达到后者的110%、103%和106%。
在韩国文化理解Hae-Rae v1.1、韩语知识CLIcK等核心韩语基准上,Upstage表示,Solar Open的成绩较DeepSeek R1高出两倍以上。与OpenAI同规模模型“GPT-OSS-120B-Medium”相比,相关基准成绩也领先100%。
在数学、复杂指令执行和Agent等高阶能力测试中,Solar Open与DeepSeek R1表现相当;与OpenAI GPT-OSS-120B-Medium相比,在综合知识和代码生成等方面也具备接近的竞争力。
Upstage表示,约20万亿个token的高质量预训练数据,是推动模型性能提升的关键因素。为弥补韩语数据相对不足的问题,公司在训练过程中引入了多种合成数据,并使用金融、法律、医疗等垂直领域专用数据,同时完善数据清洗、筛选和训练方法。
公司还表示,后续将通过韩国智能信息社会振兴院(NIA)旗下“AI Hub”开放部分数据集内容,作为公共资源对外共享,以带动本土AI研究生态发展。
在效率方面,Solar Open采用包含129个专家的MoE(Mixture-of-Experts)架构,实际计算时仅激活120亿参数。Upstage称,通过GPU优化,模型每秒Token吞吐量(TPS)提升约80%;同时借助自研强化学习框架“SnapPO”,将训练周期缩短50%。
接下来,Upstage还将与Nota、RavlUp、Plitto、KAIST、Sogang University等“自主AI基础模型项目”联盟核心成员合作,围绕“用AI开启工作的标准”这一目标,加快推进面向行业的专用服务落地。
在产业合作方面,Upstage计划与KFTC(金融结算领域)、Law&Company(法律)、Makinarocks(国防·制造)、VUNO(医疗)、Okestro(公共)、Day1 Company(教育)等领域企业合作,推动AX(AI转型)加速落地。同时,公司还将通过Allganize以及其在美国、日本的分支机构,进一步拓展全球市场。
Upstage CEO Kim Sung-hoon表示,Solar Open是公司从零独立训练出的模型,能够更深入理解韩国本土语境与语言表达,是“最具韩国特色、同时面向全球的AI”。他还表示,此次开源发布将成为开启韩国前沿AI时代的重要转折点。