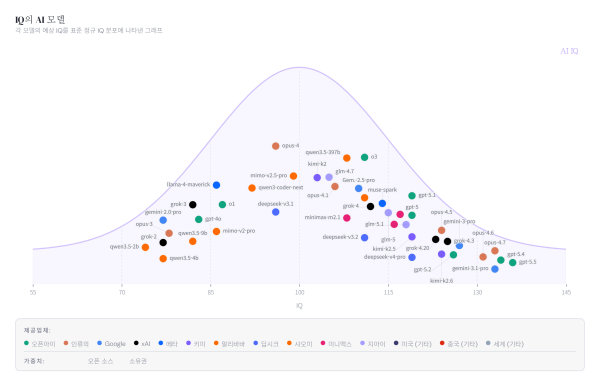
A project called AI IQ has been released to compare the performance of the latest artificial intelligence models with a single score.
On May 14 local time, online media outlet Gigazine reported that engineer and entrepreneur Ryan Shay (라이언 셰이) announced AI IQ, which converts multiple public benchmark scores into a human IQ scale.
The core of the project is to visualise where each model sits on an IQ bell curve, instead of listing complex benchmark tables as they are. Shay said he will also show how intelligence scores for state-of-the-art AI models change over time, what differences appear when IQ and emotional intelligence, or EQ, are viewed together, and what the cost is relative to intelligence in real use.
The published comparison table includes GPT-5.5, Anthropic's Claude Opus 4.7, Google Gemini 3.1, Grok 4.3, Kimi K2.6, Qwen 3.6, DeepSeek V4 and Muse Spark. As of the time of release, GPT-5.5 had the top score, followed by GPT-5.4, Gemini 3.1 Pro and Opus 4.7.
The score is not the result of an IQ test for humans. AI IQ produces an overall score by converting public benchmarks in four areas — abstract reasoning, mathematical reasoning, programming reasoning and academic reasoning — into estimated IQ values and taking the average. The benchmarks used include 12 types such as ARC-AGI-1 and ARC-AGI-2.
Some adjustment values are also included in the scoring method. For benchmarks where high scores are easy due to memorisation or contamination of training data, the project is designed so the overall score does not jump based on just one item, and where some data are missing, missing values are filled in conservatively.
It also provides comparisons by model group. For example, filtering by xAI shows only the Grok series, allowing users to see generational changes. Time-series charts show score trends, and the project also provides a screen that groups and compares only three companies: OpenAI, Anthropic and Google.
Cost comparisons are also possible. A chart of effective cost per IQ calculates costs by reflecting token-use efficiency by model on the assumption of a task using 2,000,000 input tokens and 1,000,000 output tokens. It is not a simple token unit price, but a figure closer to how much it actually costs to finish the same task. Even within the same IQ score band, Gemini was calculated to cost less than GPT and Opus.
Criticism also follows the approach of bundling AI capabilities into a single score. On X, formerly Twitter, some pointed out that AI abilities vary widely by field and that compressing them into a single score can cause misunderstandings. While AI IQ is an attempt to make benchmark tables easier to read, critics argue that estimated IQ should be seen as a converted value for comparing performance indicators rather than taken as the AI's own intelligence.
Shay said it has become difficult to understand AI models based only on benchmark tables or promotional phrases from each model. He said he wanted to make it easier to judge which models are actually worth using.
Despite the controversy, AI IQ shows a trend in which competition in generative AI is shifting beyond performance numbers and price lists toward comparisons of practical usability and efficiency. With model performance changing quickly, attention is on how showing score trends and costs together could affect model selection criteria for users and companies.