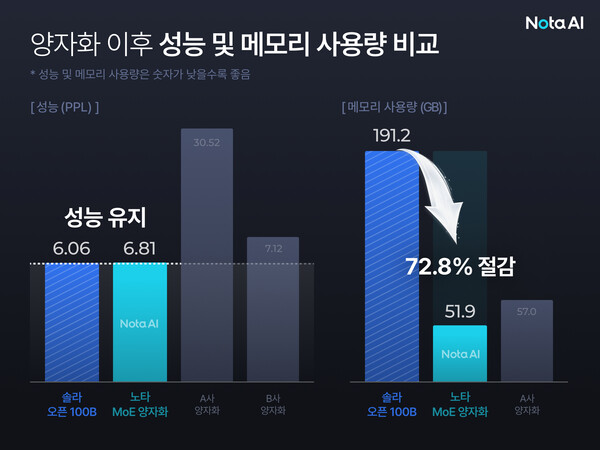
AI model optimisation company Nota said on Thursday it developed a quantisation technology that reduces memory use of Upstage's large language model (LLM) Solar 100B by 72.8%.
The technology was developed as part of the Ministry of Science and ICT-led project for an independent AI foundation model.
Nota said it independently developed a "Nota MoE quantisation" method specialised for a mixture-of-experts (MoE) structure, a next-generation LLM architecture. While existing quantisation technologies compress an entire model at once, making performance degradation unavoidable, Nota's method analyses the characteristics of each expert model and keeps parts requiring precision while compressing only less important parts.
Nota said memory use of Solar 100B fell from 191.2 GB to 51.9 GB after applying the technology. The performance indicator PPL (perplexity) came in at 6.81, remaining close to the original model's 6.06. Nota contrasted that with some general-purpose quantisation methods where performance fell by more than fivefold. Nota said it filed a patent application for the technology.
The result is expected to make it possible to deploy 100B-class models even in on-device AI environments such as robots and cars. Nota also emphasised it could help cut operating costs for companies that struggle to secure high-spec GPUs.
Nota Chief Executive Chae Myung-soo (채명수) said, "As demand grows to implement large-scale models on devices, Nota's lightweighting and optimisation technologies will play a key role."