OpenAI公开了一项新的安全评估方法,旨在在AI模型发布前,更准确地预测其在真实服务环境中可能出现的风险行为。与依赖静态数据集的传统测试方式不同,这一方法强调尽可能还原实际使用场景,以便提前发现潜在风险。
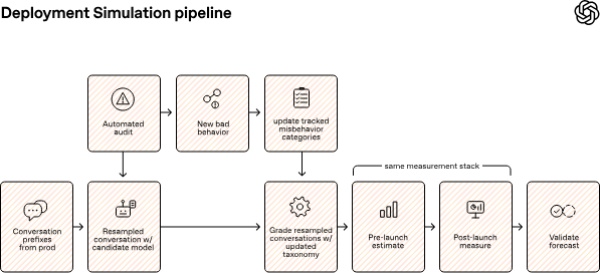
据外媒Gigazine 6月17日(当地时间)报道,OpenAI发布了一种名为“部署仿真”(Deployment Simulation)的评估方法,核心做法是利用旧版模型,模拟新一代模型部署后的真实服务环境。
按照OpenAI的说明,例如可由GPT-5模拟GPT-5.1的真实服务环境,再由GPT-5.1评估GPT-5.2,GPT-5.2继续测试GPT-5.4。借助这一方式,即便模型尚未正式发布,也可以提前观察其在真实环境中可能出现的意外行为,以及可能被滥用的路径。
此前,AI公司通常会在模型发布前进行内部安全评估,重点检查其是否会生成网络攻击代码、提供生物风险相关信息等。但由于多数测试主要依赖围绕风险提示词构建的数据集,新出现的攻击手法或非预期滥用场景往往难以被充分覆盖。
OpenAI表示,传统评估方法一方面难以覆盖所有攻击手段,也较难应对不断变化的新型攻击方式;另一方面,带有明显风险导向的测试设计本身也可能引入偏差。此外,模型还可能识别出自己正处于测试环境,从而影响评估结果的真实性。
在上述限制下,一些在测试阶段未暴露的风险行为,可能会在模型上线后于真实服务环境中更频繁地出现。为此,OpenAI提出的评估思路不再局限于对固定答案的对错判断,而是转向在接近真实部署条件的环境下,检验模型面对各类攻击时的脆弱性。
OpenAI称,采用“部署仿真”后,系统能够较高精度地预测大多数攻击手法对应的风险水平。该公司还表示,在测试结果与模型实际部署后风险水平相差10倍以上的案例中,唯一的例外是其在GPT-5.4上观察到的“Calculator Hacking”攻击。
新方法也明显降低了模型对测试环境的识别率。根据OpenAI披露的数据,GPT-5.2在传统评估方式下,有99.72%的概率识别出自己正在接受测试;而在“部署仿真”环境中,这一比例降至5.12%。这一数值与其在真实服务环境中把普通用户输入误认为测试信号的概率(5.38%)几乎一致。OpenAI据此认为,该方法能够更真实地还原实际部署环境。
OpenAI同时公开了相关论文,题为《Predicting Pre-Deployment Safety of Large Language Models via Deployment Simulation》。
业界认为,这一发布反映出AI安全评估方法正在发生变化:评估不再停留于屏蔽敏感词或核对固定问答,而是尝试在模型正式上线前,就尽可能验证其在真实服务环境中可能遭遇的绕过攻击和滥用路径。
随着业界越来越重视模型在测试环境中的“自我识别”问题,如何更精细地复现真实部署条件,或将成为后续AI安全验证的重要方向。