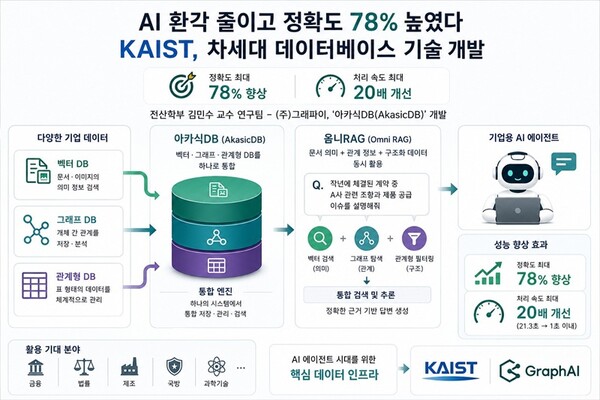
KAIST ngày 19/6 cho biết đã phát triển một công nghệ cơ sở dữ liệu tích hợp có khả năng phân tích đồng thời tài liệu, dữ liệu có cấu trúc và quan hệ giữa các thực thể, nhằm giảm hiện tượng ảo giác ở AI agent dùng trong doanh nghiệp. Theo kết quả thử nghiệm, độ chính xác câu trả lời cao hơn tối đa 78% so với RAG truyền thống, trong khi tốc độ xử lý truy vấn phức hợp được cải thiện hơn 20 lần.
Công nghệ này do nhóm nghiên cứu của giáo sư Kim Min-su thuộc Khoa Khoa học Máy tính, KAIST, phối hợp với startup Graphy phát triển. Nhóm đã giới thiệu AkashicDB, một hệ quản trị cơ sở dữ liệu tích hợp các cơ sở dữ liệu vector, đồ thị và quan hệ, cùng với giải pháp OmniRAG vận hành trên nền tảng này.
Theo KAIST, phần lớn AI agent phục vụ doanh nghiệp hiện dựa vào RAG để tìm kiếm tài liệu nội bộ và tri thức chuyên ngành trước khi tạo câu trả lời. Tuy nhiên, dữ liệu doanh nghiệp thường phân tán ở nhiều dạng khác nhau như văn bản, bảng dữ liệu và quan hệ giữa các thực thể, khiến việc tổng hợp và suy luận bị hạn chế. Đây cũng là một trong những nguyên nhân làm gia tăng hiện tượng AI đưa ra câu trả lời sai hoặc thiếu căn cứ.
OmniRAG được thiết kế để xử lý đồng thời nhiều lớp truy vấn trong một lần thực thi. Cụ thể, hệ thống kết hợp tìm kiếm vector để nắm bắt ngữ nghĩa của tài liệu, duyệt đồ thị để phân tích quan hệ giữa các thực thể, đồng thời áp dụng các điều kiện lọc trên dữ liệu quan hệ như ngày tháng hoặc loại dữ liệu. Cách tiếp cận này cho phép AI khai thác cùng lúc ngữ nghĩa tài liệu, mối liên kết giữa các thực thể và dữ liệu dạng bảng, từ đó tìm được căn cứ phù hợp hơn cho câu trả lời.
Để hỗ trợ OmniRAG, AkashicDB hợp nhất cơ sở dữ liệu vector, đồ thị và quan hệ vào một engine xử lý thống nhất. Người dùng có thể viết các truy vấn RAG phức hợp bằng SQL/GQL, sau đó hệ thống sẽ tự động tối ưu và thực thi theo một kế hoạch thống nhất. Nhờ kiến trúc này, lượng dữ liệu phải di chuyển giữa các cơ sở dữ liệu được cắt giảm, đồng thời hạn chế việc tạo ra các kết quả trung gian không cần thiết. KAIST cho biết điều này giúp giảm số lượng token mà mô hình ngôn ngữ lớn (LLM) phải xử lý, qua đó rút ngắn độ trễ phản hồi.
Trong thử nghiệm, những truy vấn tìm kiếm phức hợp vốn mất tới 21,3 giây trên các hệ thống hiện có đã được xử lý trong chưa đầy 1 giây. Mức cải thiện hiệu năng đạt hơn 20 lần. Cùng với đó, độ chính xác câu trả lời của OmniRAG cao hơn tối đa 78% so với RAG truyền thống.
Giáo sư Kim Min-su cho rằng để AI agent có thể hiểu và khai thác chính xác khối dữ liệu lớn trong doanh nghiệp, cần có một hạ tầng xử lý tích hợp dữ liệu vector, đồ thị và quan hệ trong cùng một hệ thống. Ông đánh giá nền tảng này có thể trở thành hạ tầng dữ liệu quan trọng cho các lĩnh vực đòi hỏi độ tin cậy cao như quốc phòng, sản xuất, tài chính, pháp lý, khoa học và công nghệ.
Nghiên cứu có sự tham gia của nghiên cứu sinh tiến sĩ Lee Geon-ho, Khoa Khoa học Máy tính, KAIST, với vai trò tác giả thứ nhất. Kết quả nghiên cứu đã được giới thiệu dưới dạng bài demo tại hội nghị quốc tế về cơ sở dữ liệu ACM SIGMOD 2026 hôm 2/6.