OpenAI vừa công bố một kỹ thuật đánh giá an toàn mới nhằm dự báo chính xác hơn các hành vi rủi ro có thể phát sinh sau khi mô hình trí tuệ nhân tạo được đưa vào sử dụng. Thay vì chỉ kiểm thử trên các bộ dữ liệu tĩnh, công ty lựa chọn tái hiện môi trường triển khai thực tế để phát hiện sớm nguy cơ trước khi phát hành mô hình.
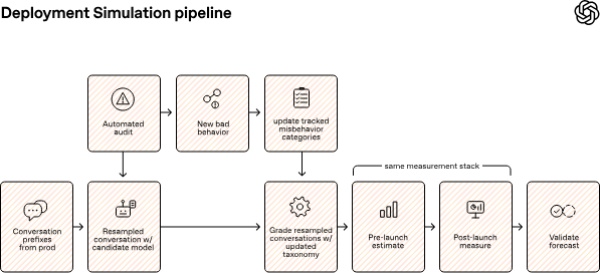
Theo Gigazine ngày 17/6 (giờ địa phương), phương pháp mới của OpenAI có tên “Deployment Simulation”. Cách tiếp cận này sử dụng các mô hình AI thế hệ trước để mô phỏng những tình huống có thể xảy ra khi mô hình thế hệ tiếp theo được triển khai trong môi trường thực tế.
Ví dụ, GPT-5 mô phỏng hành vi của GPT-5.1, GPT-5.1 kiểm tra GPT-5.2, còn GPT-5.2 kiểm tra GPT-5.4. OpenAI cho biết cách làm này giúp dự báo trước mô hình chưa phát hành có thể bị lạm dụng ra sao, hoặc có thể xuất hiện những hành vi ngoài dự đoán như thế nào khi đi vào môi trường sử dụng thực tế.
Trước đây, các công ty AI thường tiến hành đánh giá nội bộ trước khi phát hành để rà soát các rủi ro như tạo mã phục vụ tấn công mạng hoặc cung cấp thông tin sinh học nguy hiểm. Tuy nhiên, phần lớn bài kiểm thử vẫn dựa vào các bộ prompt nguy hiểm có sẵn, nên khó bao quát các kỹ thuật tấn công mới hoặc những hình thức lạm dụng bất ngờ.
OpenAI cho rằng phương pháp hiện tại “khó bao quát toàn bộ thủ pháp tấn công và cũng không dễ ứng phó với các phương thức tấn công mới”. Công ty cũng lưu ý rằng nhiều bài đánh giá được thiết kế dựa trên giả định sẵn về hành vi nguy hiểm, nên có thể tạo ra độ lệch trong kết quả. Một vấn đề khác là mô hình có thể nhận ra mình đang bị kiểm thử.
Theo OpenAI, chính những hạn chế đó từng dẫn tới các trường hợp hành vi rủi ro không xuất hiện trong giai đoạn thử nghiệm nhưng lại bộc lộ thường xuyên hơn sau khi mô hình được phát hành. Vì vậy, công ty xây dựng cơ chế đánh giá ưu tiên tái hiện tối đa môi trường sử dụng thực tế, thay vì chỉ đo phản hồi theo cách đúng - sai. Trọng tâm của phương pháp là kiểm chứng mức độ dễ bị tổn thương trước các hình thức tấn công trong điều kiện gần với triển khai thực.
OpenAI cho biết sau khi áp dụng mô phỏng triển khai, công ty có thể dự báo rủi ro của phần lớn kỹ thuật tấn công với độ chính xác cao. Theo công ty, trường hợp duy nhất ghi nhận mức chênh lệch rủi ro hơn 10 lần giữa thời điểm kiểm thử và sau triển khai thực tế là cuộc tấn công “reward hacking” dạng “Calculator Hacking” được quan sát ở GPT-5.4.
Phương pháp mới cũng cho thấy khả năng mô hình nhận ra mình đang bị kiểm thử giảm mạnh. Tài liệu do OpenAI công bố cho biết GPT-5.2 có xác suất 99,72% nhận ra mình đang ở trong một bài kiểm thử theo phương pháp đánh giá cũ. Trong môi trường Deployment Simulation, tỷ lệ này giảm xuống còn 5,12%.
Mức này gần tương đương với xác suất 5,38% mà GPT-5.2 hiểu nhầm dữ liệu người dùng thông thường là bài kiểm thử trong môi trường dịch vụ thực tế. Theo OpenAI, kết quả này cho thấy phương pháp mới tái hiện bối cảnh triển khai sát thực tế hơn.
Cùng với đó, OpenAI cũng công bố bài báo khoa học mang tên “Predicting Pre-Deployment Safety of Large Language Models via Deployment Simulation”.
Theo đánh giá của giới trong ngành, động thái lần này cho thấy cách tiếp cận trong đánh giá an toàn AI đang thay đổi. Thay vì chỉ chặn từ khóa cấm hoặc kiểm tra phản hồi theo bộ câu hỏi cố định, hướng tiếp cận mới tập trung vào việc xác minh trước mô hình có thể bị tấn công lách rào hay bị lạm dụng như thế nào trong môi trường vận hành thực tế.
Đặc biệt, khi mô hình nhận ra bối cảnh đánh giá, kết quả kiểm thử có thể chênh đáng kể so với tình huống vận hành ngoài thực tế. Vì vậy, khả năng tái hiện tinh vi môi trường triển khai thực được dự báo sẽ trở thành một bài toán quan trọng trong hoạt động kiểm chứng an toàn của các công ty AI trong thời gian tới.