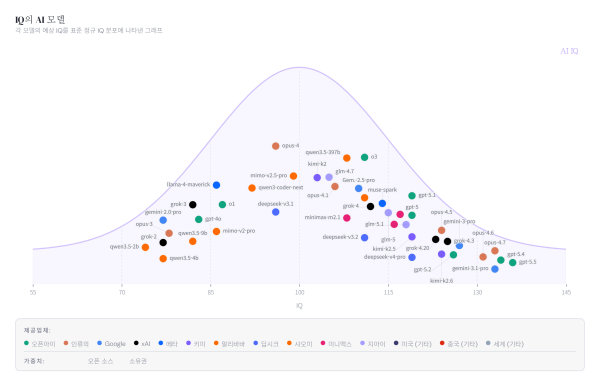
AI IQ, một dự án mới do kỹ sư kiêm nhà sáng lập Ryan Shay phát triển, đang thu hút sự chú ý với cách quy đổi các benchmark công khai của mô hình AI sang một thang IQ ước tính để so sánh hiệu năng bằng một chỉ số duy nhất.
Theo Gigazine ngày 14/5 (giờ địa phương), Ryan Shay đã giới thiệu AI IQ như một công cụ giúp trực quan hóa năng lực của các mô hình AI bằng cách chuyển nhiều điểm benchmark sang thang IQ của con người.
Thay vì để người dùng phải đọc các bảng benchmark phức tạp, AI IQ cho thấy từng mô hình đang nằm ở đâu trên “đường cong chuông” IQ. Theo Shay, dự án này còn theo dõi sự thay đổi về mức “trí tuệ” ước tính của các mô hình hàng đầu theo thời gian, đặt chúng trong tương quan với EQ và phản ánh cả chi phí sử dụng tương ứng với mức độ “thông minh”.
Bảng so sánh công khai đáng chú ý có GPT-5.5, Claude Opus 4.7 của Anthropic, Google Gemini 3.1, Grok 4.3, Kimi K2.6, Qwen 3.6, DeepSeek V4 và Muse Spark. Tại thời điểm công bố, GPT-5.5 đứng đầu, tiếp theo là GPT-5.4, Gemini 3.1 Pro và Claude Opus 4.7.
Tuy nhiên, đây không phải bài kiểm tra IQ theo nghĩa dành cho con người. AI IQ tạo ra điểm tổng hợp bằng cách quy đổi các benchmark công khai trong 4 nhóm gồm suy luận trừu tượng, suy luận toán học, suy luận lập trình và suy luận học thuật sang “IQ ước tính”, rồi lấy giá trị trung bình. Tổng cộng có 12 benchmark được sử dụng, trong đó có ARC-AGI-1 và ARC-AGI-2.
Phương pháp chấm điểm cũng đi kèm các hệ số hiệu chỉnh. Những benchmark dễ đạt điểm cao do khả năng ghi nhớ hoặc nguy cơ lẫn dữ liệu huấn luyện sẽ được xử lý để tránh làm sai lệch điểm tổng chỉ vì một hạng mục đơn lẻ. Với các trường hợp thiếu dữ liệu, hệ thống áp dụng cách ước tính theo hướng thận trọng.
Dự án còn hỗ trợ so sánh theo từng nhóm mô hình. Chẳng hạn, khi lọc theo xAI, hệ thống chỉ hiển thị dòng Grok để người dùng theo dõi sự thay đổi qua từng thế hệ. Biểu đồ theo thời gian cho phép quan sát xu hướng điểm số, đồng thời có mục so sánh riêng khi gộp ba công ty OpenAI, Anthropic và Google.
Người dùng cũng có thể đối chiếu chi phí. Biểu đồ về chi phí thực tế theo mức IQ được tính dựa trên giả định một tác vụ gồm 2 triệu token đầu vào và 1 triệu token đầu ra, sau đó tiếp tục phản ánh hiệu quả sử dụng token của từng mô hình. Vì vậy, đây không chỉ là so sánh đơn giá token, mà gần hơn với số tiền thực tế cần bỏ ra để hoàn thành cùng một tác vụ. Trong cùng một dải IQ, Gemini được tính toán có chi phí thấp hơn GPT và Opus.
Dù vậy, cách quy toàn bộ năng lực về một điểm số duy nhất cũng gây tranh cãi. Trên X, trước đây là Twitter, một số ý kiến cho rằng năng lực AI chênh lệch rất mạnh theo từng lĩnh vực, nên việc gộp lại thành một điểm có thể gây hiểu lầm. Theo quan điểm này, AI IQ có thể giúp việc đọc bảng benchmark trở nên dễ hơn, nhưng “IQ ước tính” chỉ nên được xem là giá trị quy đổi để đối chiếu chỉ số, thay vì phản ánh trí thông minh nội tại của AI.
Shay cho biết khi chỉ nhìn vào bảng benchmark hoặc các thông điệp quảng bá từ từng hãng, người dùng ngày càng khó đánh giá mô hình nào thực sự đáng dùng. Ông nói mục tiêu của AI IQ là giúp quá trình so sánh này trở nên dễ hiểu hơn.
Bất chấp tranh luận, AI IQ cho thấy cuộc đua AI tạo sinh đang dần dịch chuyển từ việc so kè điểm số và bảng giá sang so sánh tính hữu dụng và hiệu quả thực tế. Trong bối cảnh hiệu năng mô hình thay đổi nhanh, cách thể hiện đồng thời xu hướng điểm số và chi phí có thể ảnh hưởng đến tiêu chí lựa chọn mô hình của người dùng và doanh nghiệp.