[Digital Today reporter Yoonseo Lee] Chinese artificial intelligence (AI) company Z.ai has unveiled the ultralight AI model GLM-4.7-Flash, drawing attention after demonstrating performance exceeding OpenAI's GPT-OSS-20B.
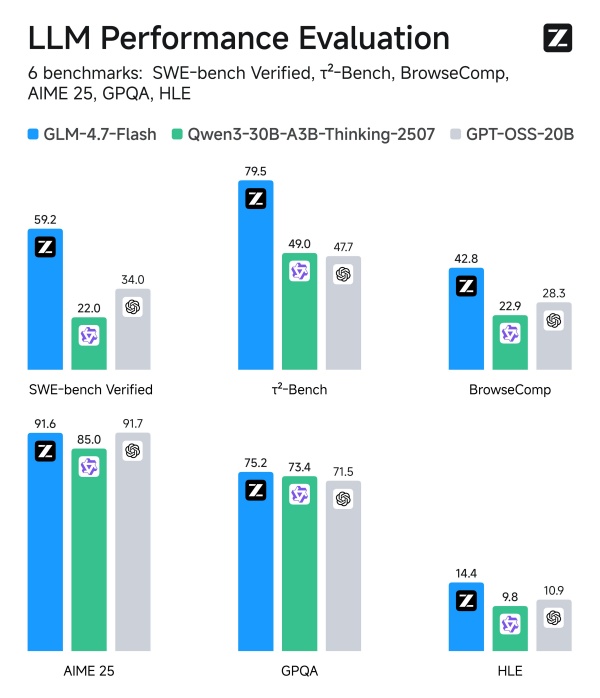
On Jan. 20 local time, online media outlet Gigazine cited major benchmark test results and reported that GLM-4.7-Flash clearly outperformed GPT-OSS-20B on key indicators including reasoning and computing capabilities.
GLM-4.7-Flash adopts a Mixture of Experts (MoE) architecture that combines multiple specialist models and has a total of 30 billion parameters. Active parameters total only 3 billion, a feature that delivers high performance while maintaining a lightweight structure.
In comparative tests against Qwen3-30B-A3B-Thinking-2507 (30 billion parameters, 3 billion active) and GPT-OSS-20B (21 billion parameters, 3.6 billion active), GLM-4.7-Flash showed overwhelming performance. It also outpaced rival models by a wide margin in the BrowseComp test measuring web browsing capability.
The model was developed as an open model and released under the MIT licence. Model data can be downloaded from Hugging Face. The BF16 version requires more than 45GB of VRAM, and a quantised version that can run on an RTX 4090 is set to be released soon.
The industry is focusing on the fact that GLM-4.7-Flash has been released under the MIT licence. The emergence of a high-performance lightweight model that can be used commercially without restriction is expected to have a significant impact on a market dominated by big tech, including OpenAI.
Expectations are also high for improved accessibility. The currently released BF16 version requires an enterprise-grade GPU, but the situation will change if the quantised version announced by Z.ai is released. If it can run on consumer graphics cards such as the RTX 4090, it is expected to lower barriers for individual developers and small and midsize companies and accelerate expansion of the open-source ecosystem.
This case shows that the flow of AI technology competition is shifting from a simple battle over size to a contest of efficiency. As lightweight models that shrink in size while boosting performance continue to emerge, an era in which ordinary users can easily use high-performance AI at home is expected to arrive sooner than anticipated.
Introducing GLM-4.7-Flash: Your local coding and agentic assistant. Setting a new standard for the 30B class, GLM-4.7-Flash balances high performance with efficiency, making it the perfect lightweight deployment option. Beyond coding, it is also recommended for creative writing,… pic.twitter.com/gd7hWQathC