Kakao said on Jan. 20 it updated Kanana-2, a next-generation language model it developed based on its own technology, and additionally released four models as open source.
Kanana-2 is a language model released as open source via Hugging Face last December. Kakao, which demonstrated high-performance and high-efficiency technological competitiveness optimised for implementing agentic AI, additionally released four models as open source with major performance updates in just over a month.
The four models released this time feature performance innovation that is both highly efficient and low cost, and a significant strengthening of tool-calling capabilities for the practical implementation of agentic AI. They are optimised to run smoothly on general-purpose GPUs at the level of Nvidia A100, rather than the latest ultra-expensive infrastructure, raising practicality so small and medium-sized companies and academic researchers can use high-performance AI without cost burdens.
At the core of Kanana-2 efficiency is a mixture-of-experts (MoE) architecture. Total parameters are 32B, maintaining the high intelligence of a large model, while activating only 3B parameters suited to the situation during actual inference to sharply improve computing efficiency. Kakao also developed several kernels essential for training MoE models, increasing training speed without performance loss and sharply reducing memory usage.
It also upgraded the data training stage as well as the architecture and data. It added a mid-training stage between pre-training and post-training, and introduced a replay technique to prevent catastrophic forgetting when the AI model learns new information. The company said this allowed it to add new reasoning capabilities while stably maintaining existing Korean-language and general common-sense capabilities.
Based on these technologies, Kakao additionally released a total of four models on Hugging Face, ranging from a base model to an instruction-following model, a reasoning-specialised model and a mid-training model. It also provided a base model for exploring mid-training that is highly useful for research purposes, increasing its contribution to the open-source ecosystem.
Another differentiator of the new Kanana-2 models is that they are specialised for implementing agent AI capable of carrying out practical work, going beyond simple conversational AI.
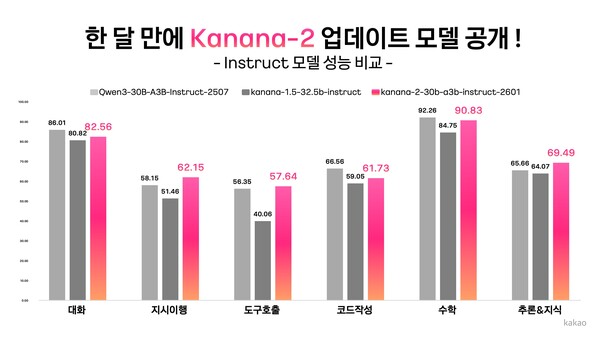
By focusing training on high-quality multi-turn tool-calling data, it significantly strengthened instruction-following and tool-calling capabilities so the model can accurately understand complex user instructions and select and call appropriate tools on its own. In performance evaluations, it recorded advantages over a peer competing model, Qwen-30B-A3B-Instruct-2507, in instruction-following accuracy, multi-turn tool-calling performance and Korean-language ability.
Byung-hak Kim (김병학), performance leader for Kakao's Kanana, said, "The renewed Kanana-2 is the result of intense consideration of how to implement practical agent AI without expensive infrastructure." He added, "By releasing as open source a model that delivers high efficiency even in common infrastructure environments, we hope it can help develop the domestic AI R&D ecosystem and become a new alternative for companies adopting AI."