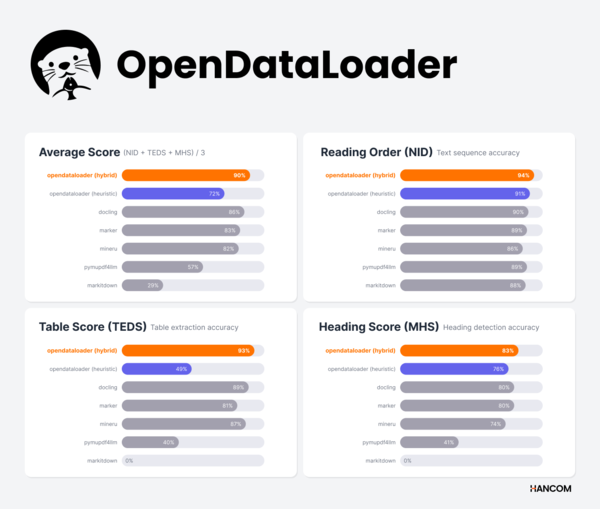
Hancom于12日宣布,正式发布开源PDF数据提取工具“OpenDataLoader PDF v2.0”。公司表示,该产品在开源PDF数据提取领域的相关基准测试中位居第一。
此次升级的核心在于混合引擎,将AI解析与直接提取能力结合起来。Hancom称,企业和开发者可在本地隔离环境中免费部署和使用该工具,从而减少数据传输至外部服务器带来的泄露风险。
据介绍,OpenDataLoader PDF v2.0内置4款免费AI插件,用于识别和提取文档中的复杂内容。其中,OCR可提升图像型PDF和扫描文档的文字识别效果;“表格提取”基于超轻量AI模型,可分析包含合并单元格在内的复杂表格结构;“公式提取”支持在本地识别科学和数学论文中的公式;“图表分析”则可将图表内容转化为文字说明输出。
Hancom表示,上述插件可兼容Docling等第三方开源AI模型。公司强调,其与相关开源项目方并不存在正式合作或赞助关系,但已确保技术兼容性,方便用户在既有技术环境中完成对接。
为提高开源透明度,Hancom已在官方GitHub代码仓库公开基准测试数据,以及可复现测试结果的详细代码。
随着此次版本发布,Hancom还将开源协议由MPL 2.0(Mozilla Public License 2.0)调整为Apache 2.0(Apache License 2.0)。公司表示,此举将以更宽松的商用条款,降低外部开发者和全球IT企业的采用门槛。
与此同时,Hancom也在推进面向AI Agent时代的生态扩展。公司已于2025年完成与LangChain的对接,并计划在2026年进一步扩大对Langflow、LlamaIndex、Gemini-cli等AI框架的适配,同时筹备支持AI Agent的MCP(Model Context Protocol)功能。
Hancom还计划于2026年下半年推出整合自研文档AI技术的商用AI插件,并新增基于AI的文档结构分析和无障碍标签自动生成功能。
Hancom CTO Jeong Ji-hwan表示,随着AI混合引擎的引入以及开源协议切换至Apache 2.0,OpenDataLoader PDF v2.0已升级为可自由使用和扩展的开放式PDF数据平台。未来,公司将通过商用AI插件和无障碍解决方案,推动全球PDF文档更好服务于AI应用,并朝着“面向所有人开放的文档”方向持续拓展全球生态。