Kakao 20日表示,公司已基于自研技术升级下一代语言模型Kanana-2,并新增开源4款模型。
Kanana-2于去年12月通过Hugging Face以开源形式发布。Kakao称,该模型在面向Agent AI的高性能与高效率技术方面具备竞争力,并在约一个月内完成一轮大幅升级,同时新增4款开源模型。
此次发布的4款模型重点提升效率与成本表现,并显著增强了面向Agent AI落地的工具调用能力。Kakao表示,相关模型已针对通用GPU进行优化,可在NVIDIA A100级硬件上运行,从而进一步提升实用性,也让中小企业和学术界研究人员能够以更低成本使用高性能AI。
Kanana-2此次效率提升的核心,在于采用了“混合专家”(MoE)架构。该系列模型总参数规模为32B(320亿),在维持大模型智能水平的同时,推理阶段仅按场景激活3B(30亿)参数,显著提高了计算效率。
Kakao还自主开发了MoE训练所需的多种内核(kernel),在不影响性能的前提下提升训练速度,并明显降低内存占用。
除架构和数据升级外,Kakao还强化了模型训练流程。公司在预训练与后训练之间新增mid-training阶段,并引入replay技术,以减少模型在学习新信息时遗忘既有知识的“灾难性遗忘”现象。Kakao表示,这使模型在新增推理能力的同时,仍能稳定保持原有的韩语能力和常识能力。
基于上述技术,Kakao此次在Hugging Face新增开源4款模型,涵盖基础模型、指令跟随模型、推理特化模型以及mid-training模型。公司还同时提供适用于研究探索的mid-training基础模型,以进一步提升对开源生态的贡献。
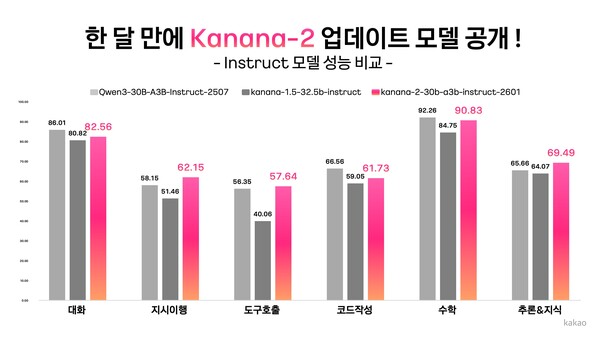
Kakao表示,新版Kanana-2的另一特点在于,其定位已不再局限于对话式AI,而是进一步面向可执行实际任务的Agent AI。
通过集中训练高质量多轮工具调用数据,新模型在指令跟随和工具调用方面的能力明显增强,能够更准确地理解复杂用户指令,并自主选择和调用合适工具。Kakao称,在实际性能评测中,与同级别模型Qwen-30B-A3B-Instruct-2507相比,新模型在指令跟随准确率、多轮工具调用表现以及韩语能力等方面更具优势。
Kakao Kanana项目负责人Kim Byeonghak表示,升级后的Kanana-2源于团队对“如何在不依赖高成本基础设施的前提下实现实用型Agent AI”的持续思考。希望通过开源在通用基础设施环境下仍可保持高效率的模型,为韩国AI研发生态的发展以及企业导入AI提供新的选择。