Nota, a company specialising in AI model slimming and optimisation, said on Thursday it succeeded in optimising a vision-language-action (VLA) model needed to implement physical AI on Qualcomm’s latest edge AI device. It cut robot action generation time by about 85.8 percent and increased inference speed by up to seven times.
A VLA model is a high-computation model that recognises real-world environments through sensors such as cameras, understands human commands and generates robot actions. It typically runs in environments based on graphics processing unit (GPU) servers, and cases of real-time execution on embedded devices alone are limited.
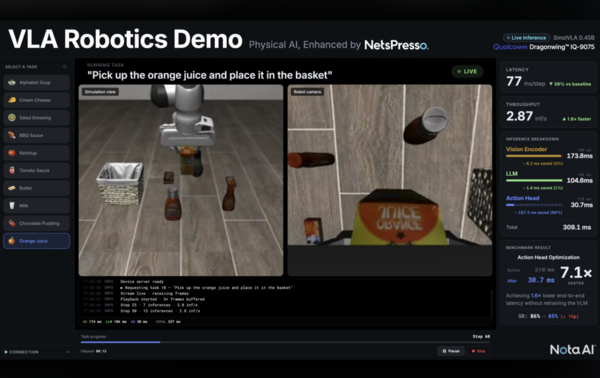
Nota ran the VLA model "SmolVLA 0.45B" on Qualcomm’s edge AI device "Dragonwing IQ-9075" and applied optimisation.
The optimisation maintained the recognition and understanding stages and focused on the final stage that generates robot actions. After applying real-time inference optimisation to reduce repetitive computation and neural processing unit (NPU)-based graph optimisation, processing time for the action generation stage (Action Head) fell to 31 milliseconds from 218 milliseconds. Total inference time was also reduced to 310 milliseconds from 505 milliseconds. Work success rates stayed at a similar level, at 85 percent versus 86 percent, Nota said.
Nota unveiled the achievement at Embedded Vision Summit 2026, held in Santa Clara, California. It ran a real-time, hands-on demonstration in which an optimised VLA model recognised an item selected by a visitor, then used a robot arm to pick it up and put it in a basket.
Nota CEO Myeong-su Chae (채명수) said, "AI needs to be able to quickly and stably process the process of seeing and understanding real environments and connecting that to actions on an edge AI device." He said, "This VLA optimisation achievement is an example showing that Nota’s technology can expand as a core foundational technology for the era of physical AI."