搜索关键词 评测体系

AI & Enterprise
Alibaba发布Qwen Image 3.0:支持最长4500 Token输入,可一次生成整版报纸排版
Alibaba发布新一代图像生成模型Qwen Image 3.0,支持最长4500 Token指令输入,可用于报纸版面、信息图和分镜等复杂文档类图像的一次成图。该模型重点强化了小字号文字、LaTeX数学公式和多语言渲染能力,定位更偏向实际办公生产力工具。不过,Alibaba此次尚未公布开源权重、技术报告、性能对比数据和API价格。

AI & Enterprise
KT cloud联手Kakao强化生成式AI安全
KT cloud宣布与Kakao启动AI安全合作,结合双方在AI基础设施与安全技术方面的能力,为客户开发和运营生成式AI服务提供更安全的支撑。首阶段,KT cloud将在面向公有云客户的RAG Suite 2.0中接入Kanana Safeguard,后续还将逐步拓展至模型评测、红队测试和运维平台等领域。
AI & Enterprise
斯坦福团队发现医疗视觉AI评测漏洞:无影像输入仍会生成诊断
斯坦福大学研究团队发现,多款医疗视觉AI在未接收病理图像、胸部X光片或脑部MRI等影像输入时,仍会描述并不存在的影像内容,并据此给出诊断。研究将这一现象称为“mirage reasoning”,并指出相关模型在传统评测基准中仍可能获得高分。为此,团队提出B-Clean方法,筛除仅凭题干即可推断答案的题目,仅保留必须依赖真实影像作答的题目。
-
AI & Enterprise
TechRadar:大模型竞争重心转向多语言能力与本土语境理解
-

AI & Enterprise
H Company发布AI代理Holo3:支持读屏并执行跨应用任务
-

AI & Enterprise
KT与KOSA达成合作 推进AICE认证升级并联合开展AI实务培训
-
AI & Enterprise
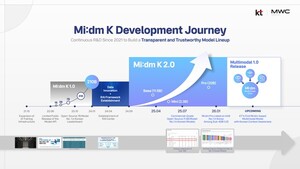
KT将携自研大模型Mi:dm K亮相MWC26,面向韩国企业及公共部门场景
-

AI & Enterprise
Hancom旗下“Hancom Assistant”获TTA AX可用性认证,加快微型Agent产品布局
-

AI & Enterprise
Flitto参与Upstage“独立AI基础模型”第二阶段项目,负责数据管理