搜索关键词 安全限制

AI & Enterprise
韩国科学技术信息通信部与KISA发布AI安全红队演练指南
韩国科学技术信息通信部与韩国互联网振兴院(KISA)联合发布《AI安全红队演练指南》,围绕提示注入、越狱、模型幻觉、代理劫持等生成式AI主要风险,提出面向企业的一线实践指引。指南同时将评估范围扩展至数据、训练链路、UI、系统提示词、API及基础设施,旨在推动行业建立常态化AI红队机制。

AI & Enterprise
CISA采用Anthropic的AI模型Mythos审查政府代码库
据路透社援引3名消息人士报道,美国网络安全与基础设施安全局(CISA)正使用Anthropic的AI模型Mythos审查政府代码库,以排查可能被外国情报人员或网络犯罪分子利用的安全漏洞。知情人士称,此次审查已发现多项安全隐患,但审查范围以及漏洞类型、严重程度等细节尚未公开。
AI & Enterprise
Anthropic将Claude Fable 5免费开放延至7月13日,付费用户可在每周额度50%内免费使用
Anthropic宣布,将面向付费订阅用户的Claude Fable 5限时免费开放活动延长至7月13日16时。延长期内,用户可在每周使用额度的50%范围内继续免费使用该模型。由于此前受美国出口管制影响,服务曾中断约18天,实际免费使用时间被压缩至约10天;不过,平台此次并未同步重置每周使用额度,部分用户因此表达不满。
-

AI & Enterprise
Sam Altman与Dario Amodei旧怨再起:从OpenAI内部分歧外溢至Anthropic创立
-
AI & Enterprise
开源AI模型GLM-5.2引安全担忧:或拉低网络攻击门槛
-

AI & Enterprise
KISA启动评估OpenAI“GPT-5.5 Cyber”,Anthropic“MYTHOS”接入推进中
-

AI & Enterprise
Anthropic发布Claude Fable 5,收紧网络安全及生物化学相关提问限制
-

AI & Enterprise
Anthropic新模型Claude Mythos公测版或于6月10日发布
-

AI & Enterprise
安全研究员称可诱导 ChatGPT 弱化护栏并生成恶意代码
-

AI & Enterprise
实测显示:借助GitHub工具数分钟内可移除Meta、Google开放权重模型安全护栏
-

AI & Enterprise
Google推出机器人模型Gemini Robotics ER 1.6,强化视觉与物理推理
-
Mobility
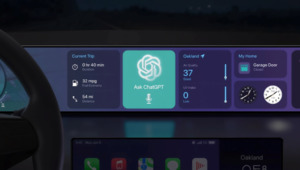
iOS 26.4支持在CarPlay中使用ChatGPT,但目前仅限语音交互
-

AI & Enterprise
Google拟开放Android侧载应用权限:可在Play Store外安装,新增多道安全验证
-

AI & Enterprise
OpenAI公开与美国防部合作细节:已设多重AI安全护栏
-

AI & Enterprise
韩国软件业人士:AI难撼软件市场,开发者岗位承压