[Digital Today reporter Yoonseo Lee (이윤서)] Chinese AI startup Z.ai has drawn market attention by releasing as open source its multimodal optical character recognition (OCR) model, GLM-OCR, specialised in document understanding.
An online media outlet, Gigazine, reported on Feb. 4 (local time) that GLM-OCR is a lightweight model with 900 million parameters, but was developed with the goal of analysing and extracting complex document layouts with high precision.
Z.ai explained that GLM-OCR is designed to understand images and text together. It combines a vision processing module that reads text and layout from photos and scans with a language processing module that organises what it reads into sentences. It added that it improved training methods to predict more information at once, boosting recognition accuracy and training efficiency.
In practice, document processing proceeds in the order of "layout analysis → text recognition". GLM-OCR is designed as a two-step method that first identifies a document's layout and then recognises text simultaneously based on that result. The company said this addresses limitations of existing OCR, in which structures were easily broken when elements such as tables and annotations were mixed, enabling recognition that considers the overall document layout.
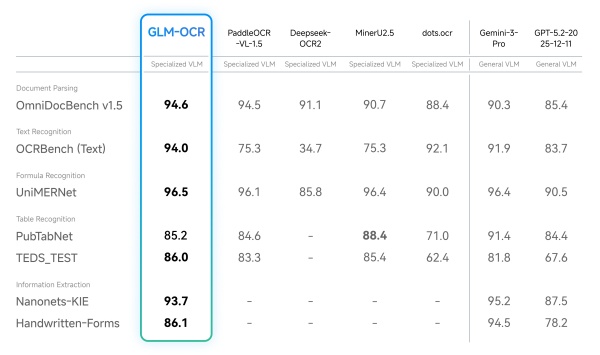
It also disclosed performance figures. Z.ai said GLM-OCR scored 94.62 in OmniDocBench V1.5, an evaluation that compares document recognition performance. It said the model also showed strong performance on difficult elements to recognise, such as formulas and tables, and on tasks that extract document contents by organising them by item.
On the operational side, it highlighted that it is a "lightweight model". Because it can run relatively quickly even in local environments such as PCs, it can process documents internally without sending them to external servers, which it cited as an advantage. Z.ai said in speed tests it processed PDFs at 1.86 pages per second and images at 0.67 per second. It added that the model is designed to recognise complex tables and documents mixing multiple languages and output results in HTML and JSON formats.
GLM-OCR was released through the "zai-org" repository on Hugging Face, an AI community. The core model is distributed under an MIT license, while an Apache License 2.0 applies to some components (PP-DocLayoutV3) used for document layout analysis.
GLM-OCR is also seen as a case that challenges the conventional view that document recognition requires heavy models. For companies, it is an attractive point that they can run OCR on internal PCs and servers without sending documents to external clouds. Interest is focused on whether practical use cases will quickly accumulate following the open-source release and whether competition in lightweight OCR will intensify further.
Introducing GLM-OCR: SOTA performance, optimized for complex document understanding. With only 0.9B parameters, GLM-OCR delivers state-of-the-art results across major document understanding benchmarks, including formula recognition, table recognition, and information extraction… pic.twitter.com/2c6iSsaXYs