OpenAI has unveiled a new safety evaluation method that more accurately predicts risky behavior that could arise in real service environments before an artificial intelligence model is released. It aims to identify risks in advance by recreating real usage conditions, moving beyond tests centered on static datasets.
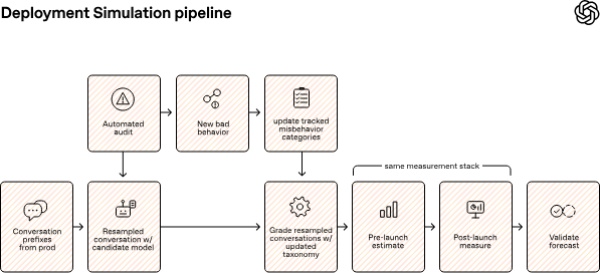
On June 17 local time, online media outlet Gigazine reported that OpenAI announced a new safety evaluation method called Deployment Simulation. The method uses older AI models to recreate in advance what it would be like if a next-generation model were deployed in a real service.
For example, GPT-5 simulates the behavior of GPT-5.1, GPT-5.1 checks GPT-5.2, and GPT-5.2 checks GPT-5.4. OpenAI said this makes it possible to confirm in advance how a not-yet-released model could be misused or show unexpected behavior in real environments.
AI companies have used internal safety evaluations before release to check potential risks such as generating code for cyberattacks and providing information related to biological risks. But tests have largely relied on datasets of risky prompts, limiting their ability to capture new attack techniques or unexpected cases of misuse.
OpenAI said existing approaches are "hard to cover all attack methods and not easy to respond to new attack methods." It also said evaluations can be biased because they are designed on the premise of risky behavior, and pointed to the problem of models recognizing that they are being tested.
Such limitations have led to cases in which risky behavior not found during testing appeared more often in real service environments after release. In response, OpenAI built an evaluation system that recreates real usage conditions as closely as possible rather than judging whether answers are correct. The focus is to verify which attacks a model is vulnerable to under conditions similar to actual deployment.
OpenAI said that applying Deployment Simulation allowed it to predict risk levels for most attack techniques with high accuracy. It said the only case where the risk level differed by 10 times or more between the test and after real deployment was a reward-hacking attack observed in GPT-5.4 called "Calculator Hacking."
The new method also sharply lowered the model's "test awareness rate." In materials released by OpenAI, GPT-5.2 recognized it was being tested with a 99.72 percent probability under the existing evaluation method. Under Deployment Simulation, the figure fell to 5.12 percent. That was close to the roughly 5.38 percent probability that GPT-5.2 would mistake normal user inputs as tests in a real service environment. OpenAI said this shows the new method recreates real deployment conditions much more realistically.
OpenAI also released a paper on the research titled "Predicting Pre-Deployment Safety of Large Language Models via Deployment Simulation."
Industry observers see the announcement as an example of change in how AI safety evaluations are conducted. They said it is an attempt to verify in advance how a model could face bypass attacks or be misused in real service environments, beyond simply blocking banned words or checking responses to predefined questions.
They also said that when AI models recognize evaluation conditions, gaps can emerge between test results and real service environments. They expect that going forward, a key task for AI companies’ safety verification will be how precisely they can recreate actual deployment conditions.