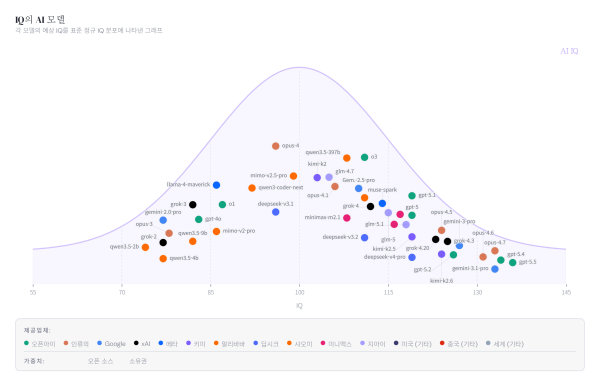
一项名为“AI IQ”的项目近日上线,试图用单一分数对最新AI模型的整体表现进行横向比较。
据Gizmodo 14日(当地时间)报道,工程师兼创业者Ryan Shay发布“AI IQ”项目,将多项公开基准成绩换算为类似人类IQ量表的“估算IQ”,并据此生成综合分数。
与传统基准榜单不同,“AI IQ”并不是简单罗列各项测试结果,而是试图将不同模型映射到IQ钟形曲线中的相对位置。Ryan Shay表示,后续还将继续展示前沿模型分数的时间变化、IQ与情绪智力(EQ)的差异,以及不同能力水平对应的实际使用成本。
目前公开的对比名单包括GPT-5.5、Anthropic的Claude Opus 4.7、Google Gemini 3.1、Grok 4.3、Kimi K2.6、Qwen 3.6、DeepSeek V4和Muse Spark等模型。按当前公布的数据,得分最高的是GPT-5.5,其后依次为GPT-5.4、Gemini 3.1 Pro和Opus 4.7。
不过,这一分数并不等同于人类IQ测试结果。“AI IQ”主要将抽象推理、数学推理、编程推理和学术推理四个领域的公开基准,分别换算为“估算IQ”后再取平均,形成综合评分。所采用的基准共12项,包括ARC-AGI-1、ARC-AGI-2等。
在评分过程中,项目还加入了校正机制。对于容易因记忆效应或训练数据混入而取得高分的基准,系统会尽量避免单项成绩过度拉高总分;在部分数据缺失时,也会采取更保守的估算方式处理。
“AI IQ”还支持按厂商或系列查看对比结果。例如,筛选xAI后可单独查看Grok系列不同代际模型的变化;时间趋势图则可用于观察分数走势。此外,平台也提供OpenAI、Anthropic和Google三家公司之间的集中对比界面。
除性能之外,项目也引入了成本维度。相关图表以200万枚输入Token和100万枚输出Token的任务为假设,在Token价格基础上结合各模型的使用效率进行测算,反映的并非单纯的Token单价,而是完成相近任务所需的实际成本。按该项目的测算结果,在相同AI IQ区间内,Gemini的成本低于GPT和Opus。
不过,用单一分数概括AI能力的做法也引发质疑。有观点认为,不同模型在各细分领域的能力差异明显,强行汇总为一个分数,可能造成误导。相关讨论普遍认为,“AI IQ”更适合作为便于横向比较的换算指标,而非对AI“智力”的直接度量。
Ryan Shay表示,单看基准榜单或厂商宣传,用户已经越来越难判断模型之间的真实差异,因此希望通过这一项目,让用户更容易识别哪些模型真正值得使用。
尽管争议仍在,“AI IQ”也反映出生成式AI竞争正在从单一性能指标和价格表,转向对实际可用性与效率的综合比较。在模型能力快速迭代的背景下,将性能趋势与成本放在同一框架下呈现,或将影响个人用户和企业的模型选型标准。